数据流
数据流(Data Stream)的现代概念最早在 1998 年被定义为“只能以事先规定好的顺序被读取一次的数据的一个序列”,之后又被修改为“只能被读取一次或少数几次的点的有序序列”,即将“一次”放松为了“几次”。你可能会觉得看不懂什么意思,但是没关系,等看完这章之后你就会对这个定义恍然大悟,现在我们先了解数据流有什么特性。
- 一般,数据流都分为输入流(Input Stream)和输出流(Output Stream),输入流只读不写,而输出流只写不读。有些数据流为了操作方便,还提供第三种,输入输出流(Input/Output Stream),既可读又可写。
- 处理系统不能控制数据的处理顺序。这里就拿普通字符串处理和字符串流处理来举例。普通字符串处理我们前面也讲过,我们可以用
string_char_at来获取任意位置的字符,可以用string_delete删除任意位置的字符,也可以用string_insert在任意位置插入字符,或者string_replace替换任意位置的字符。对于字符串流处理来说,这里假设是输入流,假如现在轮到处理第五个字符了,那我能不能读第四个字符?抱歉不能。我能不能读第六个字符?抱歉不能。你能且只能读第五个字符,因为现在字符串流正在处理第五个字符。读完第五个字符后,字符串流又会自动地跳到下一个,即第六个字符的处理,这时候才能读取第六个字符。那我能不能只读第五个字符,但是字符串流处理的位置不跳到第六个字符,而是保留在第五个字符处?抱歉也不能,因为处理系统没有权限控制数据的处理顺序。由于这种顺序处理不太方便操作,所以很多流处理都会提供seek函数,该类函数可以精确跳跃到流的某一个位置,但是要清楚,其本质还是把数据流从头开始再处理一遍,直到处理你给定的数据位置为止,再将处理权交还给你。 - 数据流的处理十分高效。假设数据是一个湖泊,我们想把里面的水移动到另一个湖里,普通的数据处理就像是一个巨大无比的袋子,一口气装下整个湖泊,转移到另一个地方,因此其负担与数据量有很大的关系。而数据流处理就是一个抽水机,我不管这个湖到底有多少水,我只抽取水管口附近的水,因为水有流动性,所以其他地方的水又会接二连三地移动到水管口,直到抽完所有水为止。理论上,数据流可以处理无穷数据的数据源。
- 数据流中的单个数据一旦被处理完就会被丢弃。这一点在第二点的例子中就可以看出来。在大型数据流处理中,通常数据的总量远远大于处理器的内存,因此,已经处理过的数据不应当还留在处理器中。注意,这里说的是从数据流中丢弃,这里依然假设是字符串流,字符串本身是占用内存的,而字符串流每次只获取字符串的一个字符保存在自己的内存中,这个内存和字符串占用的内存是分开的。处理完的字符会被丢弃,指的是字符从字符串流的内存中丢弃,而字符串本身还有这个字符。
文件
文件(File)定义为储存在磁盘上,以实现某种功能、或某个软件的部分功能为目的一个单位。例如文档文件,图像文件,音乐文件,可执行文件(程序)等。通常也会根据尾缀来命名,如 jpg 文件,mp3 文件,exe 文件等等。
文件的本质是将数据转换为二进制储存在磁盘之中。
字节(Byte)是文件大小的基本单位,1 字节等于 8 比特,即相当于能储存 0~255 一共 256 个整数数据。任何文件的大小都必须是字节的整数倍。
在电脑发展早期,曾经出现过一套用二进制储存英文字符的标准,ASCII,它规定了每一个英文字符或控制字符在内存中对应的二进制形式,如下图所示:

ASCII 码只对应 0~127,后来又提出了 IBM 扩展字符集,将编码扩展到了 0~255 一共 256 个字符,前 127 位与 ASCII 相同,在内存中用一个字节表示一个字符,充分利用了一个字节所能表示的最多数据。而之后发展出的 ANSI 则使用两个字节表示一个字符,因此最多可以表示出 65536 个不同的字符。
对于任意一个文件,都可以用 ANSI 表示出来。当你右键“用记事本打开”任意类型的文件时,通常会显示一堆乱码,如下图所示:

这就是记事本用 ANSI 编码(此处指 GBK)将文件的数据全部翻译为了字符。由于这个文件本身并不是文本文件,所以就全是乱码了。
如果使用 winHex 或其他软件,则可以看到 IBM 扩展字符集翻译的文件内容(红框部分):
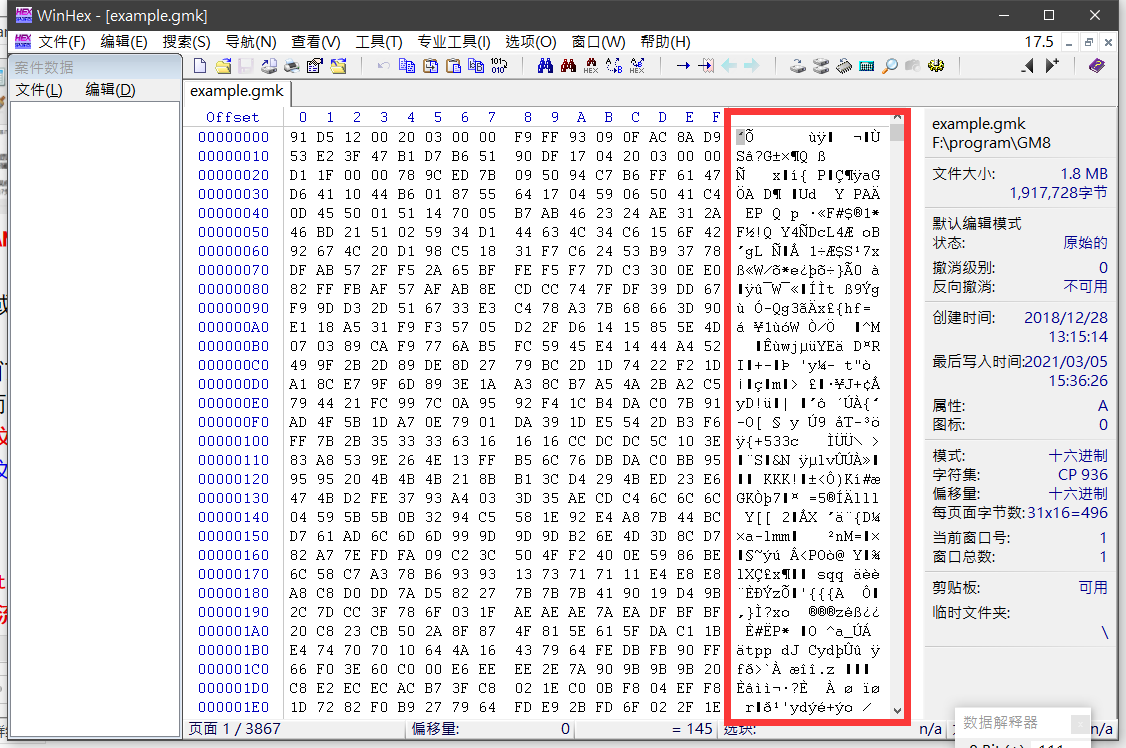
通常情况下,我们把用来储存字符数据的文件,如 txt 文件,能在正确的编码下打开看到文本信息的,称为文本文件(Text File),而本质是储存实数数据,或者程序指令(指 exe 文件),不管在什么编码下用记事本打开是一片乱码的,称之为二进制文件(Binary File)。注意,文件类型与后文提到的文件流没有直接的关系,二进制文件也可以用文本文件流打开,文本文件也可以用二进制流打开。
文件流
文件流(File stream)处理是数据流处理的一种。文件流按操作方式可以分为输入文件流(Input File Stream),输出文件流(Output File Stream),输入输出文件流(Input/Output file Stream)三种,但是一般建议输入和输出分开操作。文件流按照文件打开模式又可分为二进制文件流(Binary File Stream)和文本文件流(Text File Stream)。
二进制文件流是变长度的数据处理,假如我先写入 175(二进制 10101111),再写入 4546(二进制 00010001 11000010),那么文件的内容就是 10101111 00010001 11000010 一共三字节的大小。但是在读取这个二进制文件流的时候,我却可以先读取两个字节,再读取一个字节,即把 10101111 00010001 当成第一个数据读取出44817,再把 11000010 当成第二个数据读取出194。或者我也可以把三个字节当成一整个数据 11473346 来读出。因此,二进制文件流写入的数据和读出的数据可以不相同,如果要保证写入和读出的数据是一样的,那么就要明确每一个数据所占用的字节数。
文本文件流是定长度的数据处理,每一次数据处理所占用的字节数只和编码类型有关,比如 ASCII 一次处理一字节,Unicode(此处指 UTF-16)处理一次两个字节。因此,只要写入和读出使用同一个编码,就能保证读出的数据就是写入的数据。如果读出和写入使用不同的编码,或者用文本文件流读取非文本文件(如图像文件,视频文件),那么读出的数据一般都是无意义的乱码(但是在二进制层面上,二者还是一样的)。
注意,GM 只有字符串类型,并没有字符类型,因此将文本文件流进一步封装,每次读出/写入一整个字符串,而不能做到单字符处理。GM 在做文本文件处理时,会把换行符当做字符串的结束,因此 GM 大致上做了下面这种封装:
1
2
3
4
5
6
7
8
var c, str;
c = 读取一个字符;
while (c != chr(10))
{
str += c;
c = 读取一个字符;
}
return str;
因此,GM8 的文本文件流本质上还是一次只处理一个字符。
任何一个文件都可以用二进制文件流和文本文件流的方式打开,不管它本身到底是二进制文件还是文本文件。数据类型之间的转换是很随意的,你用 txt 随便写点文本,可以用二进制文件流打开读取实数出来用,反之亦然。
EOF
End Of File 的缩写,在 ASCII 文本文件流中表示文件的结束,本质是 -1。为什么必须是 ASCII 文本文件流呢?因为文件到达末尾之后,文件流会向处理系统返回 -1(二进制 11111111,此为负数的补码形式,二进制的第一位用来表示正负),而 ASCII 码的范围是 0~127(二进制 00000000~01111111),二进制第一位永远是 0,因此如果得到 -1 就可以肯定的说明文件结束了。但是在二进制流中,完全有可能存在 -1 或者无符号的 255(“无符号”的意思是不使用第一位二进制表示正负,因此也只能表示正数,无符号的 255 二进制也是 11111111),所以,在读取到 11111111 时,我们无法肯定到底是文件结束了呢,还是真的读到了 -1 或者无符号的 255 的数据呢。在绝大多数流处理中,都将 EOF 封装为一个函数(GM8 为 file_text_eof(file id)),其本质类似于
1
2
3
4
if (当前字符 == EOF)
return true;
else
return false;
当文件结束时,函数返回 true,否则返回 false。其本质还是判断 EOF,故而只能用于 ASCII 文本文件流。
值得注意的是,如果用文本文件流处理非 ASCII 文件(包括其他编码的文本文件,以及二进制文件)时,由于非 ASCII 文件有可能会储存 11111111 这个二进制数据,因此,当处理到这个字节时,即使离文件流结束还有十万八千里,eof 函数也会返回 true,故而,用文本文件流打开二进制文件并不是一个好的选择。
关于补码(two's complement)的知识请参考二进制。
基本流程
- 打开文件,并确定打开模式(二进制还是文本)和操作模式(输入还是输出)。
- 依次读取/写入数据或字符。
- 关闭文件。注意,文件从被打开到被关闭之前中,会处于“被占用”的状态,处于该状态的文件只能被其他程序以只读方式打开。另外,在文件流操作中,为了安全起见,输出流并不是将数据直接输出到目标文件中的,而是保存在缓存之中,直到关闭文件时才把数据从缓存中复制到文件中,如果不关闭文件,写入的数据会丢失。
文件路径
GM8提供了一些函数可以对文件路径操作,辅助文件流。
working_directory游戏的工作目录。在 .gmk 里调试游戏时指 .gmk 所在目录,生成 exe 后指 .exe 所在的目录。program_directory游戏的程序目录。指 .exe 所在的目录。当你生成 exe 发布时,在 exe 里这个变量与working_directory没有任何区别。但是在 .gmk 里调试游戏时,GM8 会在一个临时目录生成临时 exe 以供调试,调试结束会自动删除临时目录和临时 exe,此时program_directory的值是这个临时目录。temp_directory游戏的缓存目录。游戏在运行时会缓存一些内容在这个目录里,游戏结束时自动删除目录。
注意,这三个变量所代表的路径不包括最后的反斜杠。
file_exists(file)返回指定文件路径的文件是否存在。file_delete(file)删除指定文件路径的文件。file_rename(old name, new name)重新命名文件。file_copy(file, new file)复制指定文件路径的文件到 new file 路径的新文件。directory_exists(path)返回指定的目录是否存在。必须是完整路径(即以盘符开始),不能是相对路径。directory_create(path)如果目录不存在,则创建这个目录。必须是完整路径,不能是相对路径.file_find_first(mask, attr)返回第一个满足 mask 和 attr 的文件名称,如果文件不存在,会返回空字串。注意,返回的文件名不包含路径。参数 mask 是路径与文件扩展名的结合字符串,例如"C:\temp\*.doc"表示寻找C:\temp目录下的 doc 格式文件,并将找到的第一个文件的文件名返回。参数 attr(属性,attribute)用于限定搜寻的文件类型,注意,attr 只代表优先搜索,在找不到对应类型的文件时,会继续寻找其他正常的文件并返回文件名。attr 的可选值有:false无附加属性的普通文件fa_readonly只读文件fa_hidden隐藏文件fa_sysfile系统文件fa_volumeid文本文件fa_directory目录fa_archive档案fa_readonly + fa_hidden只读文件和隐藏文件。其他组合同理。如果要代表所有类型的文件,既可以全部相加,也可以使用 -1 代替。
file_find_next()返回下一个满足之前的file_find_first中的 mask 和 attr 的文件名称,如果文件不存在,会返回空字符串。file_find_close()在调用file_find_first和file_find_next时,GM 会保存搜索的进度,因此搜索完要使用这个函数释放内存。file_attributes(file, attr)返回指定路径的文件是否符合指定的 attr。filename_name(file)返回指定文件路径的文件名部分,包含扩展名。例如,filename_name("C:\temp\tt.doc")返回"tt.doc"。filename_path(file)返回指定文件路径的路径部分,包括最后的反斜杠。例如,filename_name("C:\temp\tt.doc")返回"C:\temp\"。filename_dir(file)返回指定文件路径的路径部分,不包括最后的反斜杠。例如,filename_dir("C:\temp\tt.doc")返回"C:\temp"。filename_drive(file)返回指定文件路径的盘符部分,不包括反斜杠。例如,filename_drive("C:\temp\tt.doc")返回"C:"。filename_ext(file)返回指定文件路径的扩展名,包括最前的点。 例如,filename_drive("C:\temp\tt.doc")返回".doc"。filename_change_ext(file, ext)将指定文件路径的扩展名改为新扩展名并返回。参数ext应该包含最前面的点。注意,这个函数并不是真的改了文件扩展名,仅仅只是在返回的字符串中替换了扩展名而已。使用空字符串(即"")作为新扩展名可以移除扩展名。
这里值得一提的是 file_find_first 的参数 attr,我们知道 GM8 只有实数和字符串,因此 fa_xxx 毫无疑问也是实数:
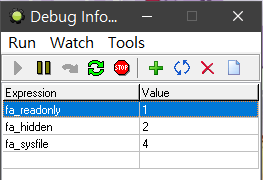
可以看到各个 attr 所对应的实数都是 2 的幂次倍,对应的二进制分别是 00000001,00000010,00000100,00001000,00010000,00100000,刚好每一个数据只有一个位是 1,当各个不同的 atrr 相加时,就相当于 1 的位相加,比如 fa_readonly(00000001) + fa_sysfile(00000100) + fa_archive(00100000) = 37(00100101)。而所有属性相加得到 63,二进制是 00111111,-1 的二进制是 11111111,因此可以用 -1 来代替 63。这种存储数据的方式叫做按位存储,关于位运算更详细的原理请参阅位运算。
以下函数会弹出消息框要求玩家选择路径,并且返回这个路径:
get_open_filename(filter, fname)弹出一个弹窗,要求玩家选择一个文件打开,返回这个文件的文件名(包含路径)。参数 fname 为默认文件名。参数 filter 为筛选方案,格式为"种类1|扩展名1;扩展名2|种类2|扩展名3....",下面是 filter 为"Image|*.png;*.jpg;*.bmp;*.ico|Vedio|*.mp4;*.flv|Text|*.txt;*.doc;*.docx"时的效果: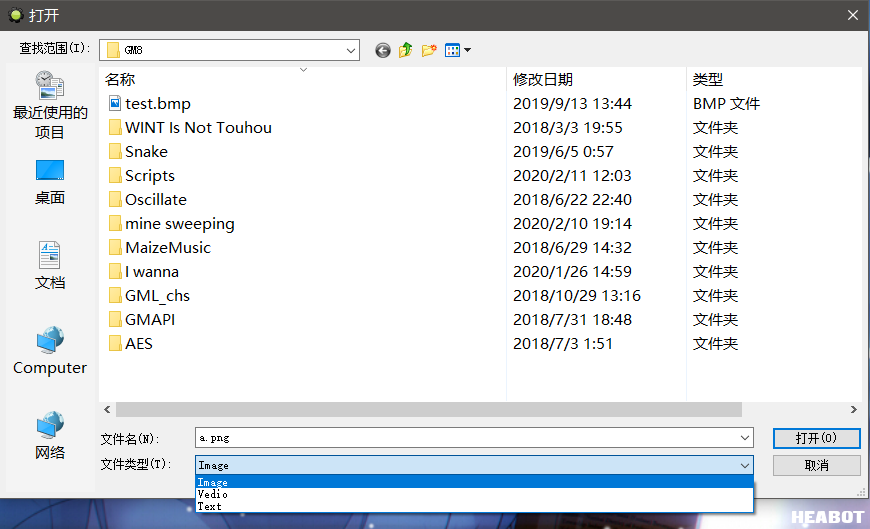
get_save_filename(filter, fname)弹出一个弹窗,要求玩家选择文件储存路径,返回这个文件的文件名(包含路径)。参数同上。
注意这两个函数不会真的打开文件,仅仅只获取路径。